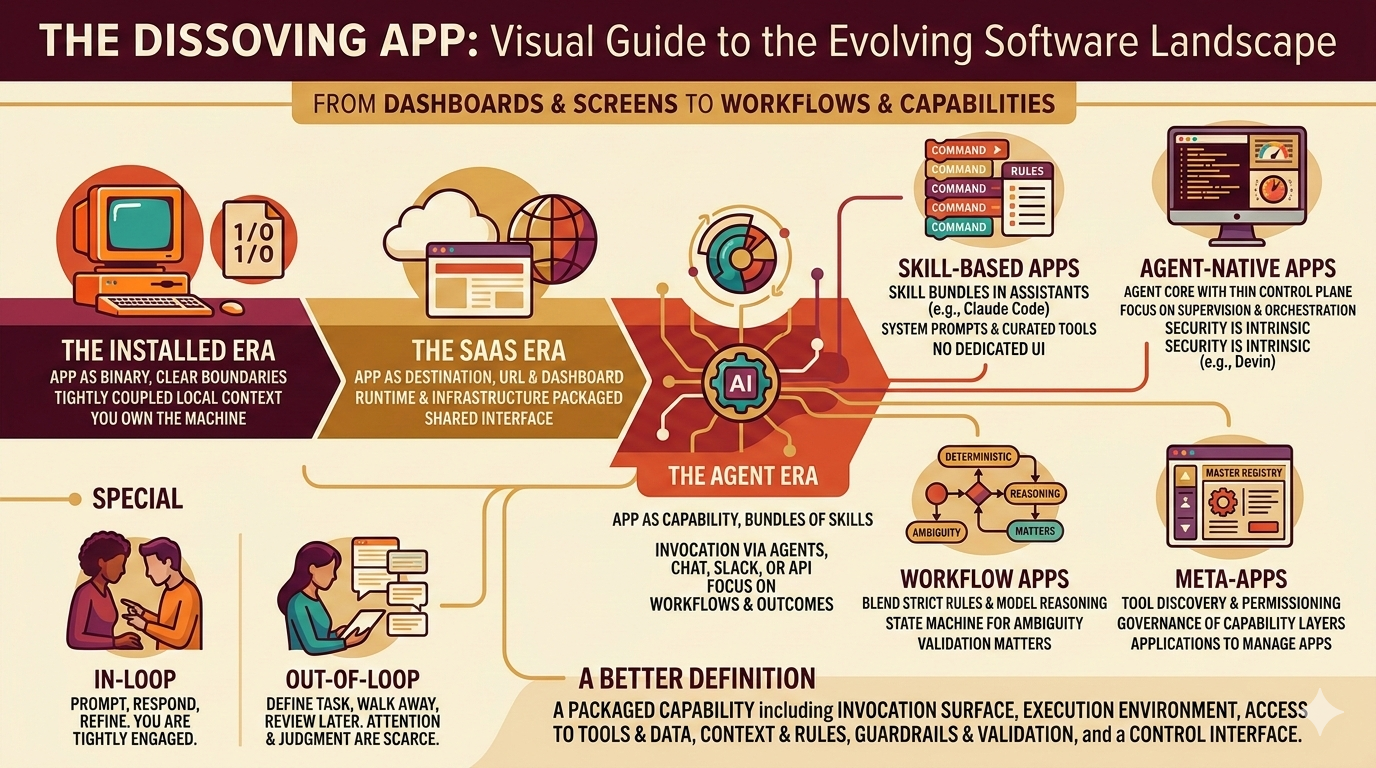
What Even Is an App?
The app isn't dying. It's dissolving. In the age of agents, software is becoming workflows, sandboxes, tool layers, and capability bundles rather than dashboards and screens.
Read articleIndependent AI development, mentoring, and product experiments.
The app isn't dying. It's dissolving. In the age of agents, software is becoming workflows, sandboxes, tool layers, and capability bundles rather than dashboards and screens.
Read article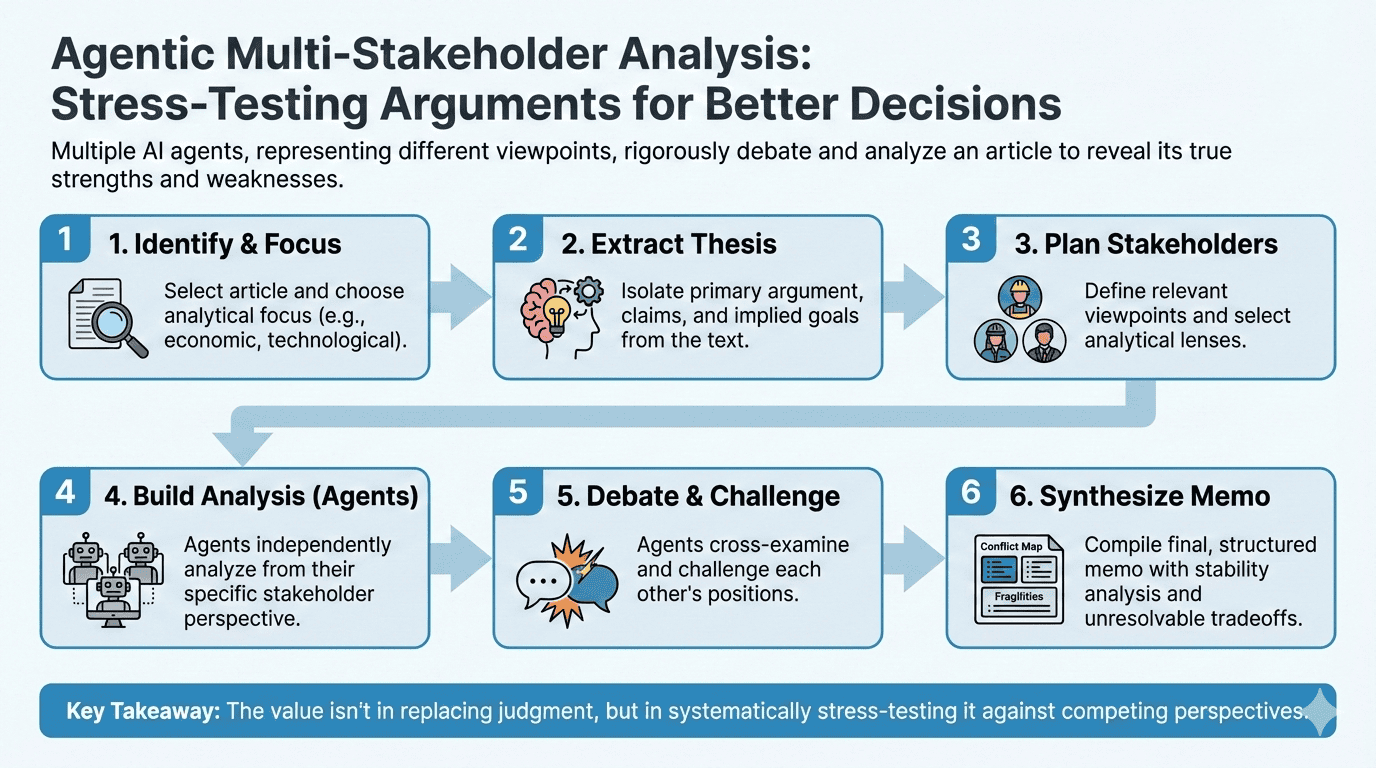
How a multi-agent analysis system stress-tests essays through stakeholder debate to reveal hidden assumptions, tradeoffs, and decision-grade conclusions.
Read article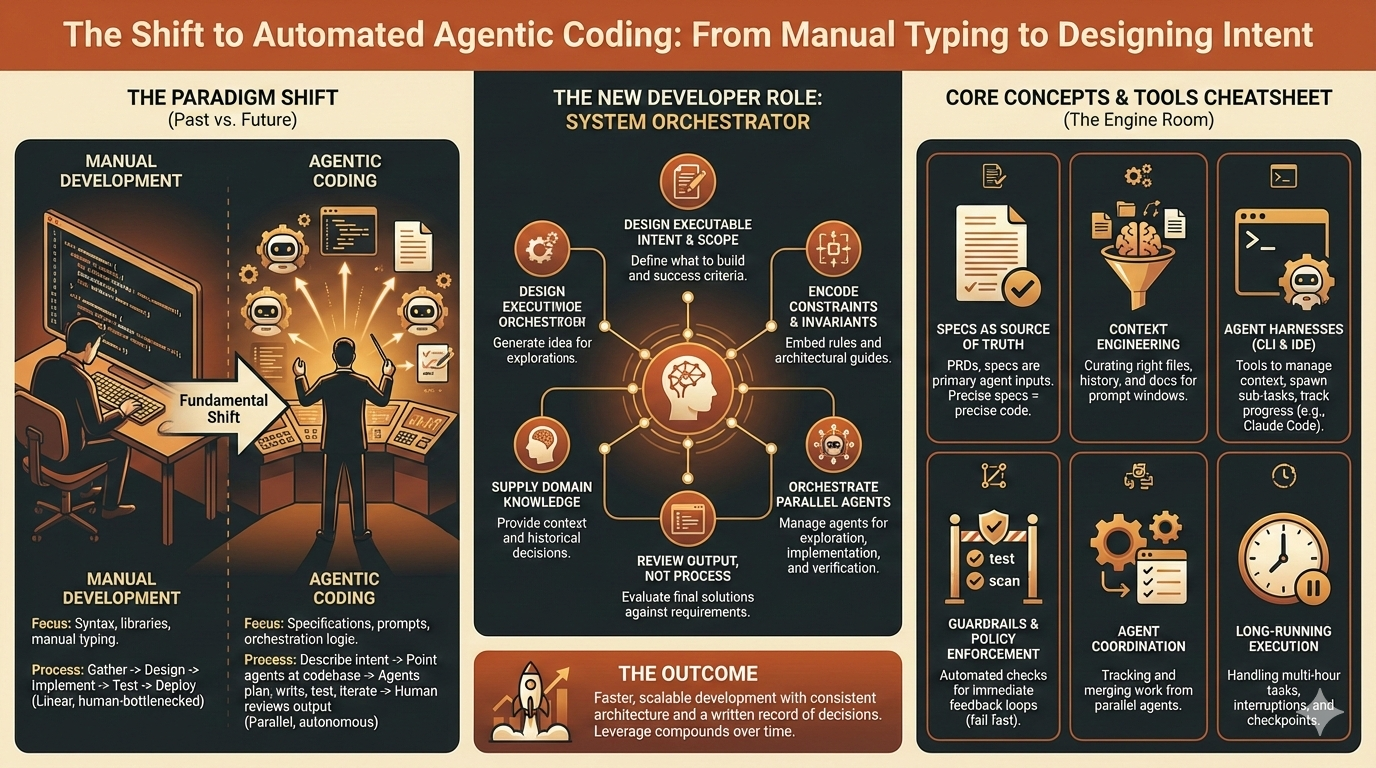
Why software development is shifting from manual coding to agent orchestration, and how teams can adapt with specs, context engineering, and autonomous work.
Read article
A practical overview of modern voice AI architectures, latency tradeoffs, streaming patterns, and design choices for real-time conversational products.
Read article
A practical developer guide to key protocols and technologies behind autonomous AI agents, from embeddings and RAG to MCP and multi-agent coordination.
Read article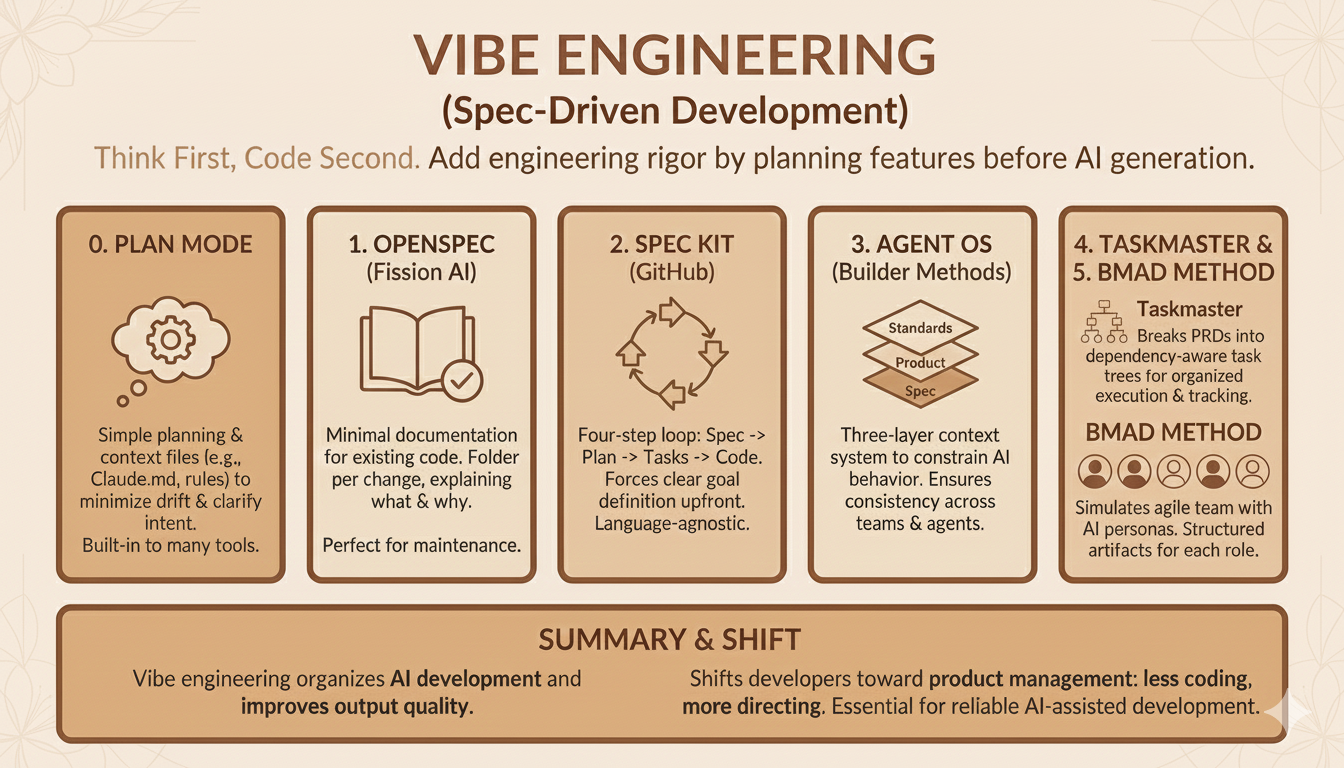
How spec-driven planning improves AI-assisted coding quality, with practical frameworks for turning vibe coding into reliable engineering workflows.
Read article