Intro to Generative AI
Recently I had the pleasure of speaking to local business and education leaders at the ChatGPT-AI Forum put on by Mountain Area Workforce Development Board of North Carolina. This is a summary of that talk.
ChatGPT
ChatGPT is a chatbot developed by OpenAI built on top of their Large Language Model (LLM) named GPT (originally v3.5 now v4). The chat part means that it responds to questions keeping a conversational context. Which is opposed to question an answer style queries and command (instruction) style requests. This under-sells ChatGPT's potential though. It is such a general and powerful model that it can and is being used for many tasks including summarization, sentiment analysis, information extraction, information reformatting, etc.
The GPT part stands for Generative Pre-trained Transformer. Which used to refer to an type of neural net architecture though now OpenAI is in the process of trademarking it for their specific brand of LLM. Note that there are other LLMs, some from Google (Palm) and Microsoft and some which are open source (Llama, Falcon, etc.) some of which are available for commercial use. It is important to check the license of the model and the data if you want to use them commercially.

Machine Learning (ML) and AI have progressed from Analytics to Generative:
- Descriptive - How many units did I sell last week?
- Predictive - How many will I sell next week?
- Prescriptive - How do I sell more in the future?
- Generative - Create a marketing/production/logistics plan to increase sales.
Generative means that, unlike a search system, it can create responses that it has not seen before.
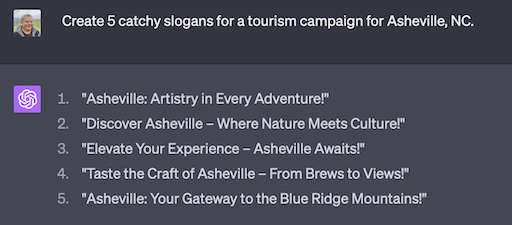
And the generation can even take stylistic requests. Though these can be challenging to control precisely.
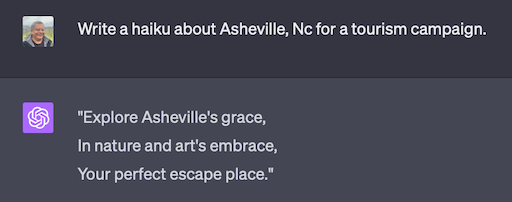
ChatGPT v4 even works with images. This functionality was demoed and planned but is not currently rolled out to the public. OpenAI has been having challenges providing enough compute power for all of the features in the announcement demo. In the demo they sketched out a web page and asked ChatGPT to generate a working html web page for it.

Lets talk about language models.
Complete this sentence:
I like to play ____.
Perhaps you said "sports", "games" or "guitar". These are all more similar to each other than the word "orangutan". This 'guess the next (or missing) word game' is how neural nets learn the similarity between words and is what it uses to predict the next word. The similarity it learns and the process of predicting the next word is a 'language model'. If you do this for a large amount of text, like the Internet and Wikipedia, you get a Large Language Model (LLM).

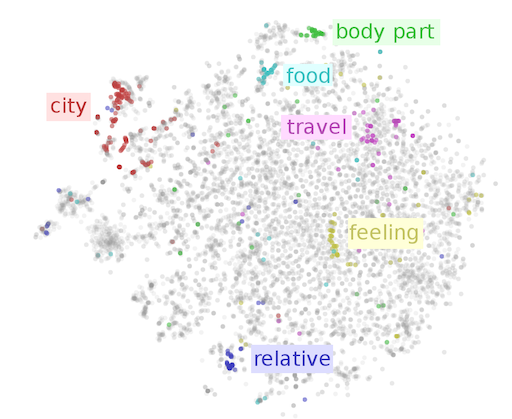
This statistical word similarity, also called an embedding, can be thought of as a point in a multi-dimensional space. Similar concepts end up being near each other in this embedding space. It's hard to visualize more than two dimensions but embeddings are often between a couple of hundred to a couple thousand dimensions to capture nuanced details.
The GPT Part
As we mentioned GPT stands for Generative Pre-trained Transformer. Transformer is the type of neural net architecture used. You may compare it to other architectures such as feed forward nets, Res-nets and U-nets. We've seen that generative means using the predictions to create responses. If we prompt the model with "What do you like to do?". It predicts that the next words could be "I like to ...". I say could because the prediction process is stochastic in that it chooses from some top most likely words resulting in some variability to the same prompt by default.

Given the amount of list articles on the Internet, a reasonable prediction for "What is the capital of England?" might be "What is the capital of France?". While this might make sense as a list of questions it is not normal human conversational style.
Consequently ChatGPT uses another training step on top of the LLM foundation model to ensure that the model will tend to create human conversational style responses. During this step humans are used to judge the best output and those judgments are used to steer the base model towards prefered answers. This process is called Reinforcement Learning from Human Feedback (RLHF),

Challenges with LLMs: Hallucinations
Note that the model is trained (optimized / rewarded) to create plausible human like responses. Not necessarily factual ones. That is it tries to generate realistic sounding answers whether or not they are accurate. This tendency to make up answers, though useful in creative endeavors, has been called 'hallucinations' in popular discussions.
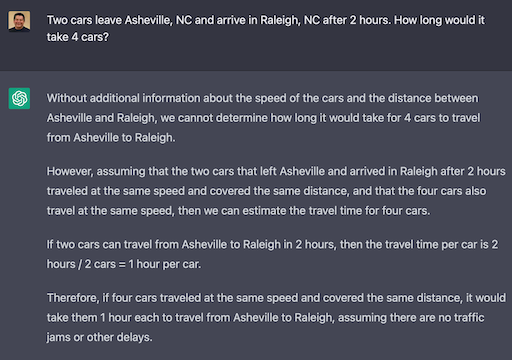
LLMs also doesn't do logic or math very well though this has improved over time and is a focus of a lot of attention.
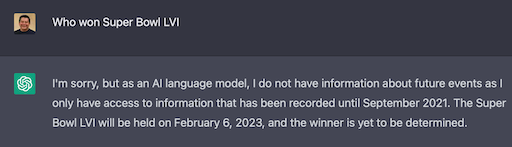
Challenge: Up To Date Data
Another challenge is that it was trained on public data up to Sep 2021 and has no knowledge of events after that date.
Challenge: Bias in Training Data
Another challenge is bias in the training data. And I don't mean just social justice and political bias but rather; whenever you select a set of information you are (un)intentionally leaving out other data. This imparts bias into the data.
For example a large part of the training data came from the internet. The internet knows a lot about cats and it knows a lot less about more esoteric topics (ie. topics that are not well represented on the internet. Such as confidential documents which every organization has).

Challenge: General vs Specific Knowledge
Relatedly, even if information on a topic is available the internet it may be drowned out by other related information that occurs in much larger volume. In this case, concensus wins and details and subtleties can get lost in the distributions.
Challenge: Copyright Concerns
I'm not a lawyer but there are some very challenging issues around fair use, learning vs copying, consent to be included in training set, source citation, etc. which are being discussed and decided by society and the powers that be.

Challenge: Security & Privacy
And finally there is the issue of security and privacy. LLMs are powerful but challenging to run locally so most will be accessed through an API. Which means that eventually your private information will be will be submitted to a third party by your accountant, lawyer or someone that just doesn't know any better.
This will bring up all sorts of privacy issues and liabilities that are currently being discussed and ironed out.

Summary: LLMs are Not a Thinking Machine
All this is to say we need to keep in mind that these are not thinking machines, though we may perceive (and then expect) them to be. As humans we anthropomorphize and attribute/expect consciousness. Additionaly, even if we had FactGPT we have to keep in mind that facts and knowledge are not wisdom.
Perhaps we can think of them as super smart auto-complete, 'stocastic parrots', or maybe a bright but over-confident 12 year old.
We need to think hard about what "trust" should mean in this context?

Strategies for Working with LLMs: Prompt Engineering
There is really nothing easy or simple about natural language. There are all kinds of shared knowledge implications in everything we say. So for now at least we can improve our results by putting some thought into how we ask (prompt) an LLM.
Prompt engineering is simply finding the prompts that work best for your use case. Some ideas include:
- Experiment with different prompts and models.
- Give it a role tell it how to respond.
- Ask it to explain itself step by step.
- Ask it to critique and rewrite its response.
- Provide relevant examples.
- Provide additional informational context in the prompt.

Strategy: In Context Learning
One strategy that can help address hallucinations, outdated information and unknown information is the practice of providing relevant information in the prompt itself. This is called In Context Learning (ICL).
Use the following pieces of context
to answer the question at the end.
If you do not know the answer,
just say that you do not know,
do not try to make up an answer.
Question: What is the company policy on X?
Resources:
... some segment of the employ handbook ...
... some memo that updates the handbook ...
... etc. ...
Strategy: Plugins & Tools
Another strategy getting a lot of attention is extending an LLM with plugins and tools so that it can get more recent information for ICL on its own and perform useful actions. These include:
- real time info: sports scores, stock prices, news
- company info: product catalog, locations, hours
- simple actions: order food, book conference room
Relatedly 'agents' are multi-step prompting programs that drive reasoning and information retrieval with tools.

Strategy: Finetuning
Finally we can consider fine tuning an LLM by continuing training data with curated from your domain. Training from scratch for your domain is expensive (probably millions of data) and would require a lot of data. Where as fine tuning could be done with a small amount of data (though more is better) and starting for a few hundred dollars.
This is the strategy used by:
- MedGPT, MedPalm
- BloombergGPT
- [YourName]GPT

Generate Everything Everywhere All at Once
In the coming years we'll be amazed by the advances in generative AI. We're essentially working on being able to generate anything from anything. Pick two from the list (and more) and you'll be able to generate one from the other:
- Text
- Images
- Video
- Audio
- Music
- 3D designs
- EEG, medical
- your data

Future of Work and Effect on Society
Will work become an iterative process with machines?
Will the programming of tomorrow will be more like writing prompts?
Will we have all media (products?) custom created on demand?
No one knows for sure.
That's what we're here to discuss.

Thank You
Image Credits
- Chat dialog from ChatGPT web app.
- Word embeddings by Chris Colah.
- Crazy images were generated by me and Stable Diffusion.