Information Retrieval for LLMs
Vector databases have been getting a lot of attention but what are vectors, what are vector databases and are they strictly necessary?
What even are vectors?
First lets start with a typical architecture for an app that uses one or more LLMs. I'm assuming that this app will use retrieval augmented prompts to provide a useful context (see this prompt engineering article) as well as manage the conversational context for the user.
The user interacts with your app and asks it a question. The ask could be an actual text question or the result of some user action like pressing a button to generate an AI response. Your app receives the request and is free to modify or enhance it or even answer it directly out of a cache or some other mechanism.
If it is to be passed on to an LLM it may be split into multiple requests or undergo back and forth with various (other) LLMs or both. Eventually a suitable response is arrived at and returned to the user.
The information that is to be used to augment the context (your corporate data) as well as the conversational memory and other miscellaneous information will be kept in one or more databases and can be added to the original prompt or any one of the subsequent prompts or even directly to the response to the user.
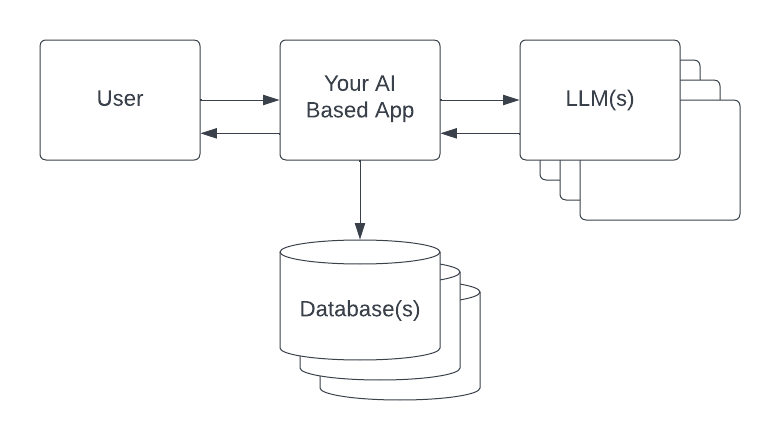
User information and conversation history can easily be kept in a traditional relational database. Your reference documents are often kept in a system that can do keyword retrieval such as a corporate Wiki, an elastic search cluster or a SQL database with a full text search capability.
The challenge then is finding the relevant information that will help the LLM answer a question.
Keyword Search
In a keyword search system if the user wanted to search for the corporate vacation policy they'd use a search term such as "vacation policy". The system would then look for documents that contained those words more or less exactly. Challenges arise with synonyms, perhaps the user used the word "leave" or "time off" instead of "vacation". These system must also handle world variations such as paint vs paints vs painter vs painting etc. Additionally these systems must decide which words are actually important to the query and drop unimportant or stop words such as "the" and "of". Most systems have strategies to address these issues that work to a varying degree.
For example, I remember one time I needed information on "how to renew a credit card". All of my searches on the corporate help desk resulted in information on "getting a new credit card" that is getting approved for a new card. It was so frustrating that they almost lost a long standing customer that day but luckily the delayed card came in the mail shortly after that.
Vectors (more specifically text embeddings) and semantic search are an attempt to address this shortcoming in keyword based search.
Vectors
Vectors are simply a list of numbers. They can represent a set of features in a record such as house information where [650000, 3, 3, 1800] stands for the price, number of bedrooms, number of bedrooms and size in square feet.
They could represent the number of words in a document where each word is given an id an the vector represents the count of those words [3, 0, 0, 5, 0, 1 ...] means that the first word occurs three times and the second zero times etc. Note that the number of words in a real world corpus can be quite large so a word count vector may be ~50k numbers (dimensions) long.
Embeddings
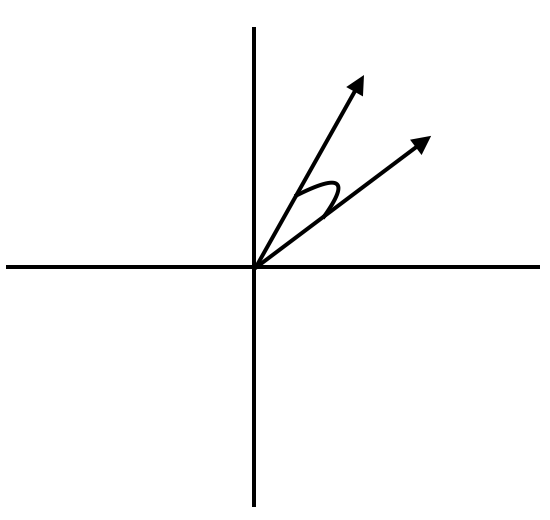
They can also be an embedding. An embedding is a learned low(er) dimensional vector. They're typically a few hundred to a few thousand dimensions (vs the tens of thousands of a word count vector). They encode a position in a domain specific space. Sometimes that space / embedding is called a latent representation because it represents some hidden information about the data and your view/use of the data. Embeddings allow similarity/semantic search via various distance metrics. The most common/useful being the cosine of the angle formed by the two vectors.
Embeddings can be created in a variety of ways. They can be similar to the feature vectors above if you take care to scale the features so that you can compare a large number, the price, with smaller numbers, the sqft, to smallest number, the number of bathrooms.
Dimensionality reduction techniques can also be thought of as embeddings. Often we have a large number of dimensions, for example images off of a stationary surveillance camera. A common approach would be to do a Principle Components Analysis (PCA) of all the pixels to come up with a base set of vectors (eigen vectors) that are mixed together in different proportions to reconstruct the original image. The proportions used for each image can be considered a type of embedding.
A more recent approach is to use the weights from a particular layer of neural net as the embedding. These are usually a layer near the end right before the classification layer of a network that has been trained to do classifications or the bottle neck layer of a (variational) auto-encoder. An auto-encoder is a network that is trained to compress data by passing it through a low(er) dimensional bottle neck layer and then reconstruct it. This bottle neck layer then has "compressed representation" that is a lot of information on what makes that data different/similar to other data.
Note that the columns of an embedding layer typically don't have human level meaning. That is you can't say the first column represents 'warmth' or 'price' or similar concept as you could with the feature vector.
Once you have these embeddings there are several very useful things you can do with them. As we mentioned you can find the distance between a query vector and another set of vectors to find the most similar ones. This will give you the most similar document, image, song, etc. So it is possible to find all the restaurant reviews that mention the ambiance for example. This can also be used as a k-nearest neighbor style classifier. Which lets you label a restaurant based on the reviews. It's also possible to create clusters and reduce the dimensionality even further to visualize the clusters of items and their relationships. Another use is anomaly detection where you check if an embedding vector lies near known/expected other vectors.
Text Embeddings
Text embeddings really took off with Word2Vec, GLoVe and Bert style word embeddings. These created embedding vectors at the word level. I'm sure we've all seen the king - man + woman = queen examples from Efficient Estimation of Word Representations in Vector Space, 2013 Mikolov et al..
Single vectors for words had the challenge of representing words that have multiple meanings (Polysemy) such as bank of a river and bank of international settlements as well as word challenges with word order. Dog bites man. vs Man bites dog.
Various encoders have been developed to handle sentences, paragraphs and short passages including sentence transformers, OpenAI and Cohere embeddings. These are the ones most commonly used today. The embedding functions can usually only handle a maximum number of tokens/words so longer documents are split up in to smaller chunks and each chunk is encoded. The vectors for each chunk can then be used to find other related chunks.
Vector Databases
That's where vector databases come in. We're all familiar with databases that let you retrieve records based on various values such as houses under $500,000 and we've just described how vectors can be used to do similarity based searches. However if we have large number of documents or document chunks or if our collection changes on a regular basis, keeping track of the embeddings and doing a preformant search can become tricky. That is where Vector databases like ChromaDB, Pinecone, Weaviate and others come in. They manage the vector collection and organize it for efficient queries and updates.
Some vector databases can run in process (for example ChromaDB and libraries like Faiss and Annoy), others can run on your infrastructure (ChromaDB, and others) and others are hosted by third parties. Which is best is use case specific.
Challenges
Retrieval augmented generation works pretty well for a lot of cases. Some things to keep in mind are:
-
Embedding an unprocessed question may not be the most efficient representation of what the user is looking for. That is they're probably not interested in other questions that are similar to their question but rather answers or text chunks that might contain the appropriate information.
-
Questions often have a lot of implicit assumptions or unspoken knowledge. A good listener/guide/mentor is able to envision what the user is really trying to ask or what assumptions are causing them to ask in this particular way. That kind of wisdom is not implicit in vector embeddings.
-
Partitioning the documents into chunks is often done by an arbitrary number of words or tokens. This may split concepts across chunks or create chunks with multiple concepts. It might be useful to investigate other ways to create chunks such as page, paragraph or other topic boundaries.
-
The off the shelf embeddings are a great start and will work well for most applications. However, if you have an unusual dataset, different kind of data or want to get the best performance keep in mind that it is possible to create embeddings specifically for your corpus or your dataset perhaps by using techniques such as auto encoders.
Conclusion
I hope this was helpful. Go forth and manipulate your prompts and augment with relevant data for the best possible results. Let me know if you have any questions.
Thanks.