Your company's brain shouldn't live in people's heads
How small teams can capture institutional knowledge and turn it into context their AI tools can use, from personal second brains to a shared company brain.
Think about the last time someone on your team was out for a week. How many small decisions stalled because the one person who knew how something worked wasn’t around to ask? How a particular client likes to be invoiced. Why you give one customer a pricing exception and not another. The workaround for the vendor whose system never sends a confirmation. That knowledge runs your business, and most of it lives in people’s heads and scattered files. When someone leaves for good, a chunk of it walks out the door with them.
“Write down your processes” has been the standard advice forever, and almost nobody finds the time to write them, update them, or read them. AI changes the math. A well-kept record of how your team works is no longer just onboarding material for the next hire. It’s something an AI agent can read and act on every single day, which changes what that record is worth.
If you use AI tools, you already know the friction. Before the model can do anything useful, you carry the whole situation into it: paste the email, explain who the client is, say which version of the deck is current, mention that yesterday’s Slack thread changed the decision. The model is capable the moment you finish, but getting it there takes ten minutes every time. A company brain does that work once, in a place the AI can read on its own. And there’s a bigger shift underneath: as models get cheaper and good-enough options pile up, the advantage stops being who has the smartest model and becomes who has the context that makes any decent model useful. Much of the current jockeying between the big AI companies is a fight over exactly that.
The idea is showing up under a pile of names: second brains, agent wikis, the “company brain.” They’re circling the same thing, and the differences matter once you start deciding what to do about it.
The idea behind all the names
A second brain is the older personal-knowledge idea, popularized by writers like Tiago Forte and tools like Obsidian and Notion. It’s a place outside your head where you stash notes, ideas, and references so you can find them later. It’s built for a person to read.
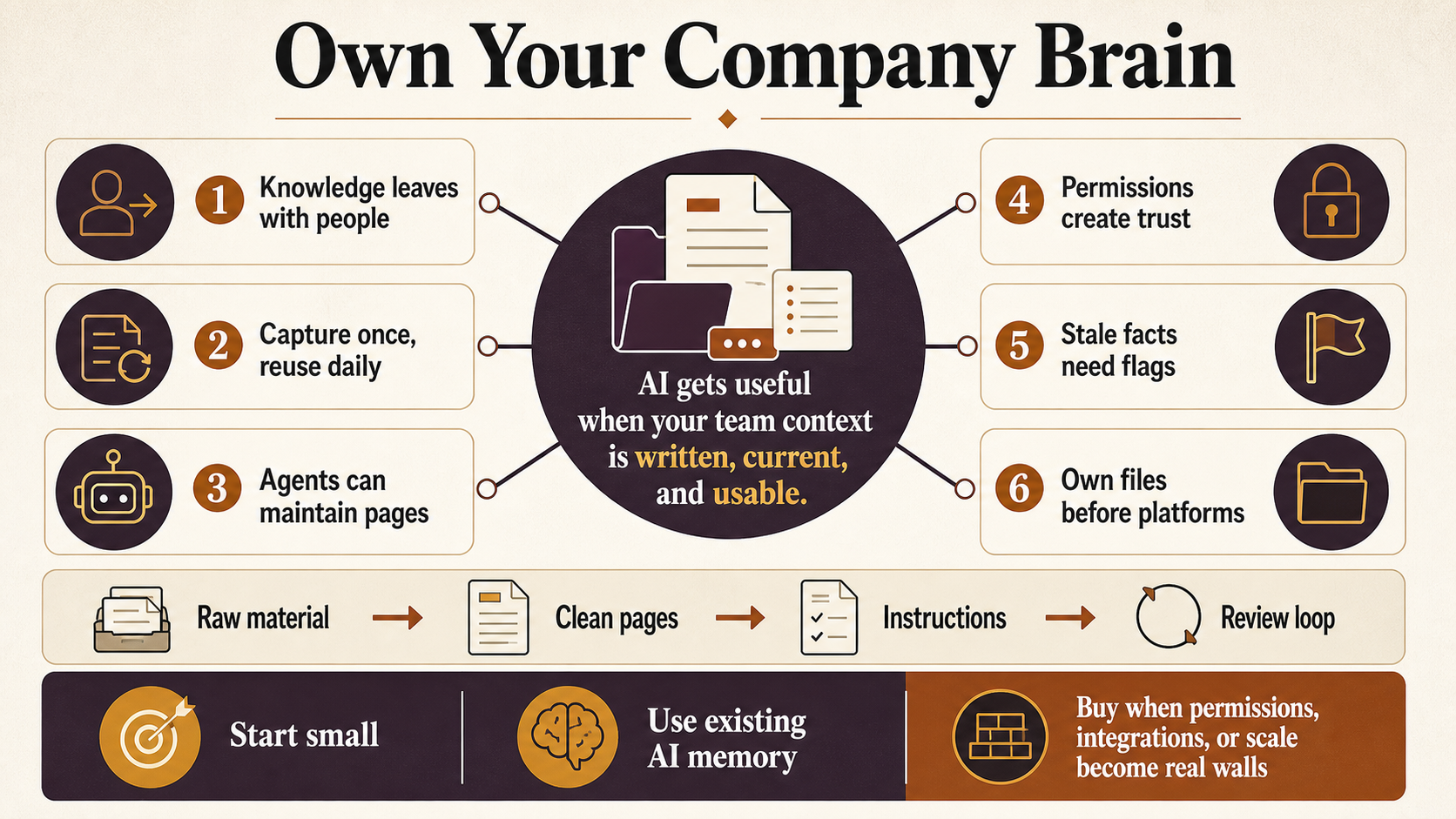
A Karpathy wiki, or LLM wiki, is newer. In April 2026, AI researcher Andrej Karpathy described spending most of his AI usage not on writing code but on building knowledge bases. The setup: you drop raw source material into one folder (articles, transcripts, notes), and an agent writes a structured wiki from it in another, with summary pages, concept pages, and links between them. Then the agent maintains it. It connects related pages, flags places where two sources disagree, and runs periodic checks for stale or missing information. His example grew to around 100 articles and 400,000 words. The shift from a second brain is that the agent does most of the writing and upkeep, and the result is built to be read by an agent as much as by a person.
A company brain is the team version. Y Combinator put it on its Summer 2026 list of startups it wants people to build: a system that pulls knowledge out of all your fragmented sources, keeps it current, and turns it into something AI agents can act on. Less “a wiki you go search” and more a living model of how the company actually works, used by both people and software to get things done.
The thread running through all three is the same: get knowledge out of heads and chat logs and into a structured, maintained, searchable, agent-usable form. And the agents can help build and keep it.
The version already inside your AI tools
If anyone on your team uses AI coding or work assistants, they’ve probably touched an early version of this without calling it that. For example Claude has two kinds of memory. One is a file you write by hand (literally called CLAUDE.md) with plain-language instructions: how you like things done, your conventions, the “always do this” rules. It loads every time you start. The other is an auto-memory file the assistant writes to itself, jotting down what it learned so it can pick it up next session. One layer is what you tell it; the other is what it figures out and remembers.
OpenAI’s Codex has the same shape with different labels: a hand-written AGENTS.md file for your instructions, and a “Memories” feature that summarizes past sessions and reads them back later. (One detail if you’re in Europe: at launch the auto-generated memory wasn’t available in the EU, UK, or Switzerland, so users there got only the file they write themselves.)
This makes the concept concrete. A plain text file of instructions, plus a file the agent updates on its own, is the same architecture as a company brain, shrunk to one person and one project. It’s also where most people will feel this idea for the first time. The catch is that these memories are siloed. They live inside one tool, scoped to one user. They don’t give your whole team a single shared source of truth that everyone, and every agent, can rely on.
A second brain for one person
The smallest real version is something you could stand up yourself this week. The Karpathy-style setup looks like this:
- A folder of raw material. Meeting transcripts, PDFs, saved emails, notes, docs. Whatever comes in.
- A folder of clean pages the agent writes from that raw material. One page per topic, customer, process, or decision, with links between related pages.
- A short instructions file telling the agent how to organize things, what to summarize, how to link pages, and when to flag something as stale or contradictory.
- A loop. You drop new material in, the agent updates the right pages and the index, and every so often you ask it to review the whole thing for gaps and inconsistencies.
Besides the wiki, Notion is where a lot of people start, and it’s a reasonable choice: easy, cloud-based, friendly to non-technical folks. But you build the whole structure yourself, the databases, the templates, the maintenance. My own opinion: I’m not sure you need that scaffolding anymore. If an agent is doing the writing, the linking, and the upkeep, the elaborate structure is work the agent can do for you against plain files you own. A folder of markdown files in something like Obsidian, with an agent pointed at it, fits the way this actually works better than a hand-built Notion workspace does. The trade-off to weigh is ownership: local files you control versus cloud convenience you rent.
This is genuinely useful for one person. It is not yet a team system. The moment a second person needs to read, edit, or trust it, a new set of problems shows up.
Sharing it with a team, where it gets hard
Going from one brain to a team brain is not “put the folder on a shared drive.” Team knowledge is a different kind of thing. The context you feed an AI on your own is formal: a file you picked, a prompt you wrote, tidied up before it goes in. Team knowledge is informal, shared, half-written, permissioned, often stale, and scattered across six places. That messier material is what a team brain has to take in, and it changes several things at once.
Permissions and trust. Not everyone should see everything: salaries, client contracts, security procedures. A shared brain needs some notion of who can read and write what. The bigger commercial tools are built around this. A DIY folder isn’t.
Keeping it current. A personal brain stays fresh because one person feeds it. A team brain goes stale unless updating it is baked into how work already happens, or an agent is doing the upkeep. Stale knowledge that looks authoritative is worse than no knowledge, because people act on it.
Conflicts and a single source of truth. When two people document the same process two different ways, which one is right? Much of the value in the agent-maintained approach is that it surfaces those contradictions instead of letting them sit buried in two docs.
Sources you can check. For your team to rely on a page, and for an agent to act on it safely, the page needs to point back to where the fact came from.
Pulling from where knowledge actually lives. Real institutional knowledge is spread across email, Slack or Teams, shared docs, your CRM, spreadsheets. A team brain is only as good as how much of that it can take in and keep synced.
What you can buy today
You don’t have to build any of this from scratch. The market sorts roughly by the job each tool is doing. (Prices move fast here, so treat these as ballpark and check before you commit.)
Personal and small-team knowledge bases. Notion (with Notion AI as roughly a $10 per user per month add-on) and Obsidian (free for personal use, paid for sync and commercial use). Lightest lift, but you supply the structure and the upkeep, and with an agent doing the work, that hand-built scaffolding matters less than it used to.
What’s already inside the office suite you pay for. Many small teams already run Microsoft 365 or Google Workspace, and both now include an AI layer that reads your company’s own data. Microsoft 365 Copilot grounds itself in your Microsoft Graph (emails, chats, calendars, files) and runs about $30 per user per month on top of a qualifying plan. Google’s Gemini in Workspace does the equivalent across Gmail, Drive, and Docs, with bundles landing somewhere in the $48 to $60 per user per month range depending on tier. For a lot of teams the first “company brain” is just switching on what they’re already paying for. The limit: these read and answer over your existing pile of files. They don’t build you a clean, maintained knowledge layer.
Enterprise search, or “work AI.” Glean is the name you’ll hear, a permissions-aware knowledge graph that searches across all your apps. Pricing isn’t public, but reported contracts run into five figures a year, roughly $25 to $50 per user per month. Built for larger organizations, and probably both overkill and overpriced for a team of five to fifteen.
Agent-first platforms. Dust (from about $15 per user per month) gives people and AI agents a shared workspace over company knowledge, with agents that take action rather than just answer questions. Amazon Q Business ($20 per user per month for Pro, $3 for Lite) and ChatGPT’s team and enterprise tiers sit nearby, each tied to its own ecosystem.
The new “company brain” startups. A wave of young companies is building exactly the structured-knowledge-for-agents idea. They’re the closest thing to the Karpathy-wiki-for-a-company vision, and also the least proven. I’d watch the category rather than bet a team on any single early product right now.
There’s a real gap in this map. The enterprise tools assume scale and budgets most small teams don’t have, and they optimize for search and compliance over the lightweight, agent-maintained, you-own-the-files approach. Small teams end up stranded between “personal second brain” and “enterprise platform.”
How to decide: build, buy, or wait
Rather than hand you an answer, here are the questions that tend to sort it.
- How much of your knowledge is already written down versus only in people’s heads? If almost nothing is captured yet, start with the habit and a simple tool before you buy a platform. The tool won’t fix a missing habit.
- How sensitive is your data, and where is it allowed to live? For some teams (client confidentiality, regulated work) keeping things local or on-device matters a lot. That narrows your options quickly.
- Who is going to keep it current? If the answer is “nobody really has time,” lean toward a setup where an agent does the upkeep, and be skeptical of anything that depends on people diligently updating it by hand.
- Are you optimizing for finding answers, or for getting work done? Search is one job. Having agents actually do work off your knowledge is another. They point you toward different tools.
- How much lock-in can you live with? Owning plain files versus renting a cloud platform is a real trade-off for something this central to how you operate.
If I had to give a small team a default: start small and own your files. Stand up a personal or team second brain, build the habit of capturing things, use the memory features already in the AI tools you have, and only move up to a heavier platform when you hit an actual wall, like permissions or integrations or scale. Capturing the knowledge well is the hard part and the lasting asset. The tool you read it with can change later.
Where this is going
Institutional knowledge is moving from something you hoped to write down someday into infrastructure your AI tools depend on to be useful. If the race really is shifting from who has the smartest model to who has the best context to point it at, that context is yours to own. The teams that capture, maintain, and govern what they know will have something competitors can’t easily copy, and their AI tools will be a good deal more useful for it.
The gap I keep coming back to is the one small teams fall into: stuck between a personal second brain and an enterprise platform, wanting something local-first, agent-maintained, and actually owned. It’s an interesting space, and I’m building something that may help. So how does your team capture what it knows today? What’s worked, and what’s quietly fallen apart? If that’s a problem you’re feeling, I’d like to hear how you’re thinking about it.