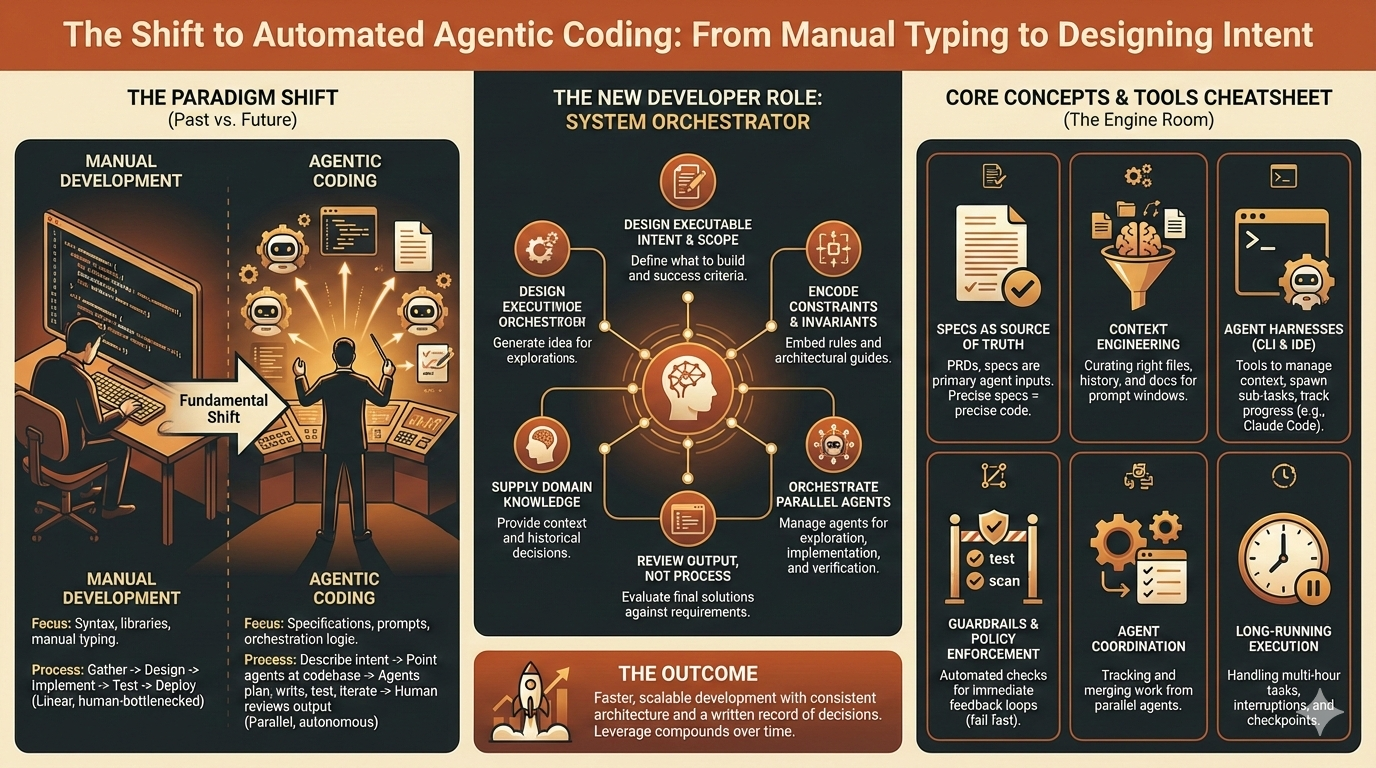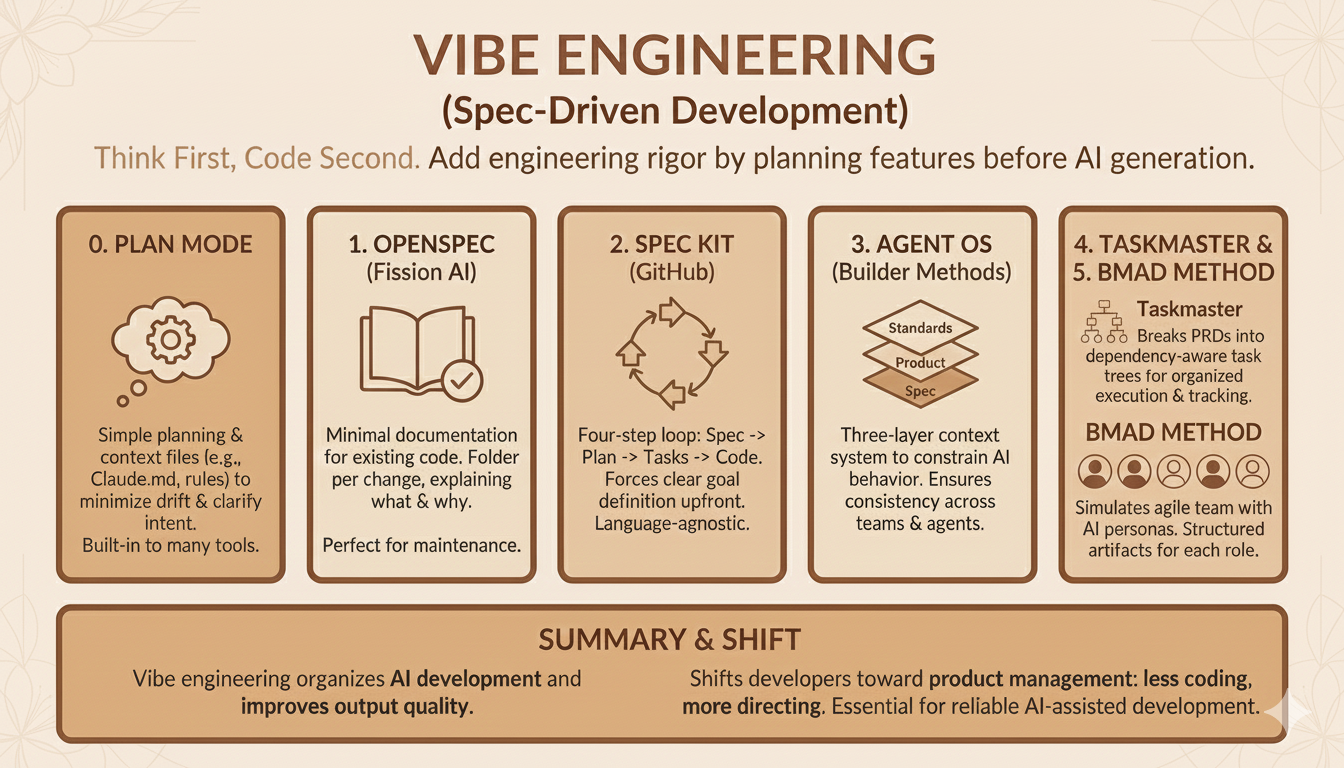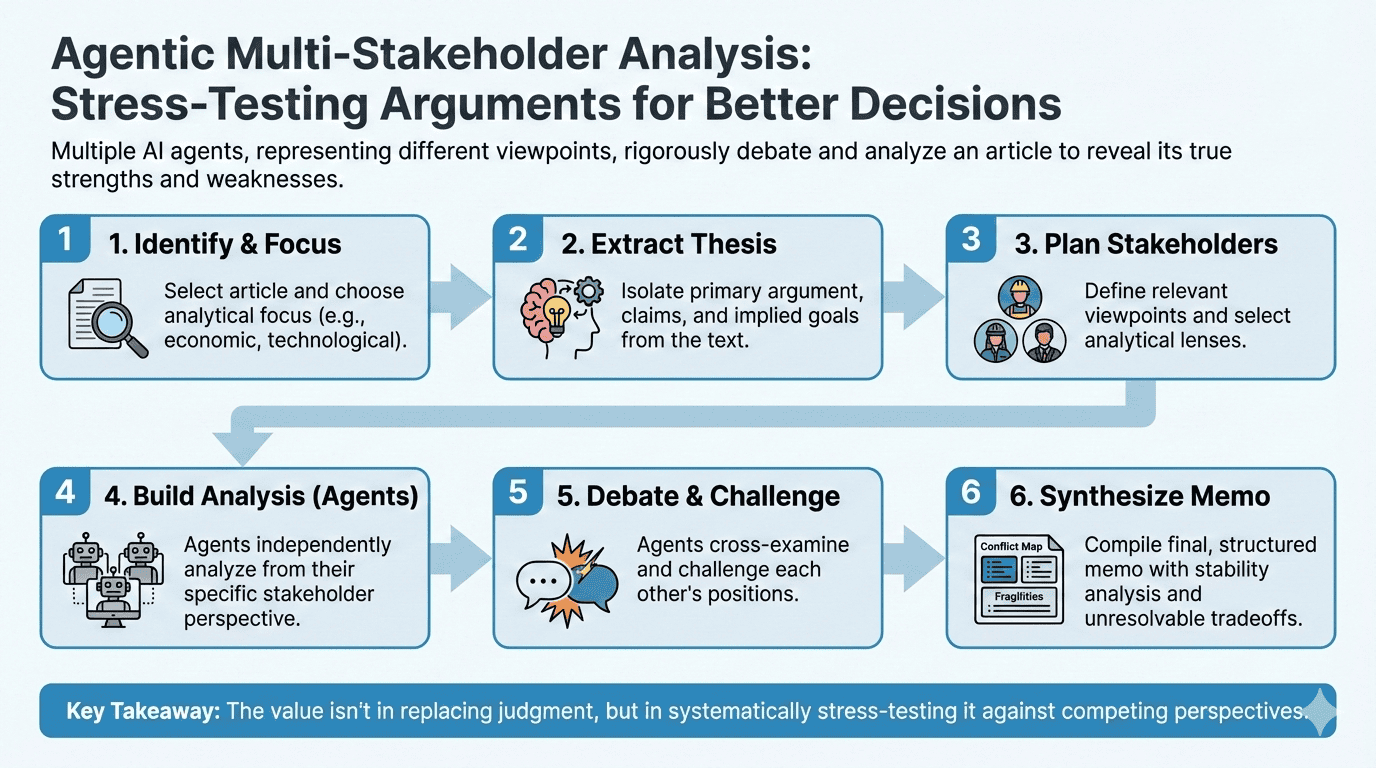
Agentic Multi-Stakeholder Analysis
A system that uses multiple LLM agents each representing a different stakeholder perspective to analyze articles, debate each other's positions, and produce structured memos that stress-test arguments from every angle that matters. For anyone who cares about decision quality and wants to see what a convincing argument looks like after it survives real scrutiny.
Read article